Exciting news! TCMS official website is live! Offering full-stack software services including enterprise-level custom R&D, App and mini-program development, multi-system integration, AI, blockchain, and embedded development, empowering digital-intelligent transformation across industries. Visit dev.tekin.cn to discuss cooperation!
The LZW (Lempel-Ziv-Welch) algorithm achieves efficient lossless compression by dynamically building a string-to-code mapping dictionary, making it widely used in image formats, data transmission, and other fields. Its key advantage lies in high compression ratios for data with repeated patterns, though attention must be paid to dictionary management and data feature matching.
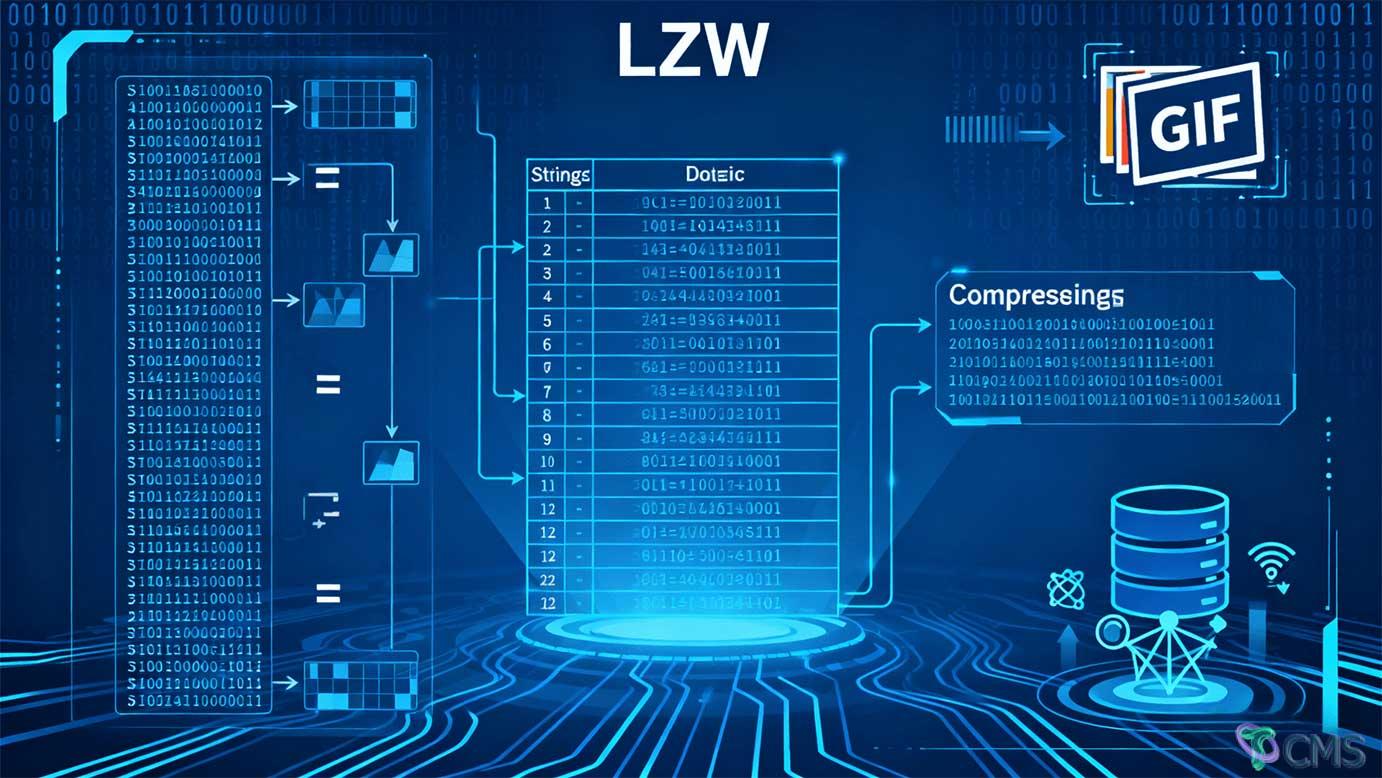
The LZW (Lempel-Ziv-Welch) algorithm achieves efficient lossless compression by dynamically building a string-to-code mapping dictionary, making it widely used in image formats, data transmission, and other fields. Its key advantage lies in high compression ratios for data with repeated patterns, though attention must be paid to dictionary management and data feature matching.
As a dictionary-based lossless data compression algorithm, the core idea of LZW is to replace repeatedly occurring long strings with short codes, enabling efficient compression through dynamic dictionary construction.
Dictionary Initialization: At the start of encoding, the dictionary contains all possible single characters (e.g., 0-255 in the ASCII table), each mapped to a unique initial code (e.g., character 'A' corresponds to 65).
Encoding Process: Continuously read characters from the input data to form the longest string S already present in the dictionary, then output its code. Next, add S + next character as a new entry to the dictionary, update S to the next character, and repeat until the data is fully processed.
Decoding Process: The initial dictionary is identical to that used during encoding. Read the code values and output the corresponding string S. Meanwhile, concatenate the first character of the previously output string with the current string to add as a new entry to the dictionary, gradually restoring the original data.
Example: When encoding "TOBEORTOBEORTOBEOR", the dictionary dynamically records combinations like "TO" and "TOB", ultimately replacing repeated long sequences with short codes to achieve compression.
The core logic of implementing the LZW algorithm is consistent across different programming languages: all follow the basic LZW workflow, including initializing a dictionary with all single characters, dynamically adding new combinations, and handling edge cases in compression and decompression.
package main
import (
"fmt"
)
// Compression function
func lzwCompress(data string) []int {
// Initialize dictionary
dictionary := make(map[string]int)
for i := 0; i < 256; i++ {
dictionary[string(rune(i))] = i
}
nextCode := 256
currentStr := ""
var compressed []int
for _, char := range data {
combined := currentStr + string(char)
if _, exists := dictionary[combined]; exists {
currentStr = combined
} else {
compressed = append(compressed, dictionary[currentStr])
dictionary[combined] = nextCode
nextCode++
currentStr = string(char)
}
}
// Process remaining string
if currentStr != "" {
compressed = append(compressed, dictionary[currentStr])
}
return compressed
}
// Decompression function
func lzwDecompress(compressed []int) string {
if len(compressed) == 0 {
return ""
}
// Initialize dictionary
dictionary := make(map[int]string)
for i := 0; i < 256; i++ {
dictionary[i] = string(rune(i))
}
nextCode := 256
currentStr := dictionary[compressed[0]]
var decompressed string
decompressed += currentStr
for _, code := range compressed[1:] {
var entry string
if val, exists := dictionary[code]; exists {
entry = val
} else {
entry = currentStr + currentStr[:1]
}
decompressed += entry
dictionary[nextCode] = currentStr + entry[:1]
nextCode++
currentStr = entry
}
return decompressed
}
func main() {
original := "TOBEORTOBEORTOBEOR"
compressed := lzwCompress(original)
decompressed := lzwDecompress(compressed)
fmt.Printf("Original Data: %s\n", original)
fmt.Printf("Compressed: %v\n", compressed)
fmt.Printf("Decompressed: %s\n", decompressed)
fmt.Printf("Compression Ratio: %.2f\n", float64(len(compressed)*2)/float64(len(original)*8))
}def lzw_compress(data: str) -> list[int]:
# Initialize dictionary with all single characters
dictionary = {chr(i): i for i in range(256)}
next_code = 256
current_str = ""
compressed = []
for char in data:
combined = current_str + char
if combined in dictionary:
current_str = combined
else:
# Output code for current string
compressed.append(dictionary[current_str])
# Add new combination to dictionary
dictionary[combined] = next_code
next_code += 1
current_str = char
# Process the final string
if current_str:
compressed.append(dictionary[current_str])
return compressed
def lzw_decompress(compressed: list[int]) -> str:
if not compressed:
return ""
# Initialize dictionary
dictionary = {i: chr(i) for i in range(256)}
next_code = 256
current_str = chr(compressed[0])
decompressed = [current_str]
for code in compressed[1:]:
if code in dictionary:
entry = dictionary[code]
else:
# Handle edge case: new combination not in dictionary
entry = current_str + current_str[0]
decompressed.append(entry)
# Add new combination to dictionary
dictionary[next_code] = current_str + entry[0]
next_code += 1
current_str = entry
return ''.join(decompressed)
# Usage example
if __name__ == "__main__":
original = "TOBEORTOBEORTOBEOR"
compressed = lzw_compress(original)
decompressed = lzw_decompress(compressed)
print(f"Original Data: {original}")
print(f"Compressed: {compressed}")
print(f"Decompressed: {decompressed}")
print(f"Compression Ratio: {len(compressed)*2 / (len(original)*8):.2f}") # Assuming 2 bytes per codeimport java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class LZW {
// Compression method
public static List<Integer> compress(String data) {
// Initialize dictionary
Map<String, Integer> dictionary = new HashMap<>();
for (int i = 0; i < 256; i++) {
dictionary.put(String.valueOf((char) i), i);
}
int nextCode = 256;
String currentStr = "";
List<Integer> compressed = new ArrayList<>();
for (char c : data.toCharArray()) {
String combined = currentStr + c;
if (dictionary.containsKey(combined)) {
currentStr = combined;
} else {
compressed.add(dictionary.get(currentStr));
dictionary.put(combined, nextCode);
nextCode++;
currentStr = String.valueOf(c);
}
}
// Process remaining string
if (!currentStr.isEmpty()) {
compressed.add(dictionary.get(currentStr));
}
return compressed;
}
// Decompression method
public static String decompress(List<Integer> compressed) {
if (compressed.isEmpty()) {
return "";
}
// Initialize dictionary
Map<Integer, String> dictionary = new HashMap<>();
for (int i = 0; i < 256; i++) {
dictionary.put(i, String.valueOf((char) i));
}
int nextCode = 256;
String currentStr = dictionary.get(compressed.get(0));
StringBuilder decompressed = new StringBuilder(currentStr);
for (int i = 1; i < compressed.size(); i++) {
int code = compressed.get(i);
String entry;
if (dictionary.containsKey(code)) {
entry = dictionary.get(code);
} else {
entry = currentStr + currentStr.charAt(0);
}
decompressed.append(entry);
dictionary.put(nextCode, currentStr + entry.charAt(0));
nextCode++;
currentStr = entry;
}
return decompressed.toString();
}
public static void main(String[] args) {
String original = "TOBEORTOBEORTOBEOR";
List<Integer> compressed = compress(original);
String decompressed = decompress(compressed);
System.out.println("Original Data: " + original);
System.out.println("Compressed: " + compressed);
System.out.println("Decompressed: " + decompressed);
System.out.printf("Compression Ratio: %.2f%n", (double) (compressed.size() * 2) / (original.length() * 8));
}
}<?php
function lzwCompress($data) {
// Initialize dictionary
$dictionary = array();
for ($i = 0; $i < 256; $i++) {
$dictionary[chr($i)] = $i;
}
$nextCode = 256;
$currentStr = "";
$compressed = array();
for ($i = 0; $i < strlen($data); $i++) {
$char = $data[$i];
$combined = $currentStr . $char;
if (isset($dictionary[$combined])) {
$currentStr = $combined;
} else {
$compressed[] = $dictionary[$currentStr];
$dictionary[$combined] = $nextCode;
$nextCode++;
$currentStr = $char;
}
}
// Process remaining string
if ($currentStr !== "") {
$compressed[] = $dictionary[$currentStr];
}
return $compressed;
}
function lzwDecompress($compressed) {
if (empty($compressed)) {
return "";
}
// Initialize dictionary
$dictionary = array();
for ($i = 0; $i < 256; $i++) {
$dictionary[$i] = chr($i);
}
$nextCode = 256;
$currentStr = $dictionary[$compressed[0]];
$decompressed = $currentStr;
for ($i = 1; $i < count($compressed); $i++) {
$code = $compressed[$i];
if (isset($dictionary[$code])) {
$entry = $dictionary[$code];
} else {
$entry = $currentStr . $currentStr[0];
}
$decompressed .= $entry;
$dictionary[$nextCode] = $currentStr . $entry[0];
$nextCode++;
$currentStr = $entry;
}
return $decompressed;
}
// Usage example
$original = "TOBEORTOBEORTOBEOR";
$compressed = lzwCompress($original);
$decompressed = lzwDecompress($compressed);
echo "Original Data: " . $original . "\n";
echo "Compressed: " . implode(", ", $compressed) . "\n";
echo "Decompressed: " . $decompressed . "\n";
echo sprintf("Compression Ratio: %.2f\n", (count($compressed)*2 / strlen($original)*8));
?>
using namespace std;
// LZW compression function
vector<int> lzw_compress(const string& data) {
// Initialize dictionary with all single characters
map<string, int> dictionary;
for (int i = 0; i < 256; ++i) {
dictionary[string(1, static_cast<char>(i))] = i;
}
int next_code = 256;
string current_str;
vector<int> compressed;
for (char c : data) {
string combined = current_str + c;
// If combined string exists in dictionary, continue extending
if (dictionary.find(combined) != dictionary.end()) {
current_str = combined;
} else {
// Output code for current string
compressed.push_back(dictionary[current_str]);
// Add new combination to dictionary
dictionary[combined] = next_code++;
current_str = string(1, c);
}
}
// Process the final string
if (!current_str.empty()) {
compressed.push_back(dictionary[current_str]);
}
return compressed;
}
// LZW decompression function
string lzw_decompress(const vector<int>& compressed) {
if (compressed.empty()) {
return "";
}
// Initialize dictionary with all single characters
map<int, string> dictionary;
for (int i = 0; i < 256; ++i) {
dictionary[i] = string(1, static_cast<char>(i));
}
int next_code = 256;
string current_str = dictionary[compressed[0]];
string decompressed = current_str;
for (size_t i = 1; i < compressed.size(); ++i) {
int code = compressed[i];
string entry;
// Look up string corresponding to current code
if (dictionary.find(code) != dictionary.end()) {
entry = dictionary[code];
} else {
// Handle edge case: code not yet in dictionary
entry = current_str + current_str[0];
}
decompressed += entry;
// Add new combination to dictionary
dictionary[next_code++] = current_str + entry[0];
current_str = entry;
}
return decompressed;
}
int main() {
// Test data
string original = "TOBEORTOBEORTOBEOR";
cout << "Original Data: " << original << endl;
// Compress
vector<int> compressed = lzw_compress(original);
cout << "Compressed Codes: ";
for (size_t i = 0; i < compressed.size(); ++i) {
if (i > 0) cout << " ";
cout << compressed[i];
}
cout << endl;
// Decompress
string decompressed = lzw_decompress(compressed);
cout << "Decompressed Data: " << decompressed << endl;
// Verify data integrity
if (original == decompressed) {
cout << "Verification: Compression and decompression successful, data matches exactly" << endl;
} else {
cout << "Verification: Error, data does not match" << endl;
}
// Calculate compression ratio
double original_size = original.size() * 8; // Assuming 8 bits per character
double compressed_size = compressed.size() * 12; // Assuming 12 bits per code
double compression_ratio = compressed_size / original_size;
cout << fixed << setprecision(2) << "Compression Ratio: " << compression_ratio << " (" << compressed_size << " bits / " << original_size << " bits)" << endl;
return 0;
}Dictionary Size Control: For large input data, the dictionary may grow indefinitely. Set a maximum number of entries (e.g., 4096) and reset the dictionary when full to balance compression ratio and memory usage.
Preprocessing Optimization: LZW performs poorly on low-redundancy data (e.g., random binary data). Preprocess with hashing or grouping to improve repeated pattern recognition.
Encoding Format Selection: Store compressed codes using variable-length integers (e.g., 12-bit, 16-bit) to reduce redundant bits and further minimize size.
File Compression: Used in GIF images and TIFF formats, ideal for handling repeated pixel sequences.
Communication Protocols: Real-time compression of text, logs, etc., during data transmission to reduce bandwidth consumption.
Database Storage: Compress storage of repeated fields (e.g., user addresses, category tags) to save space.
Fluctuating Compression Ratios: Achieves over 50% compression for high-redundancy data (e.g., HTML source code) but may inflate low-redundancy data. Select algorithms based on data characteristics.
Dictionary Synchronization Dependency: The dictionary construction process must be identical for encoding and decoding; otherwise, decompression errors occur. Ensure consistent initial dictionaries and update logic on both sides.
Computational Overhead: Dynamic dictionary lookups and updates (especially hash table operations) may impact performance, making LZW suitable for small to medium-sized data processing.
Feb 25, 2026

May 03, 2025

May 03, 2025

Please enter your email address below and click the subscribe button. By doing so, you agree to our Terms and Conditions.
