喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
AI看似在思考、推理和理解,实际上却在进行复杂的概率计算。语言模型的运作原理只有一条:根据上下文预测最可能出现的下一个词。本文拆解ChatGPT等系统的token预测机制,解释为何AI能回答复杂问题却并不真正理解。核心洞察是:AI擅长模式识别和语言结构,而非理解。当AI写代码、写论文、做解释时,它只是在套用学到的格式,而非展示理解能力。"语言智能"与"认知智能"的根本区别,解释了为何AI可以听起来权威却完全错误。
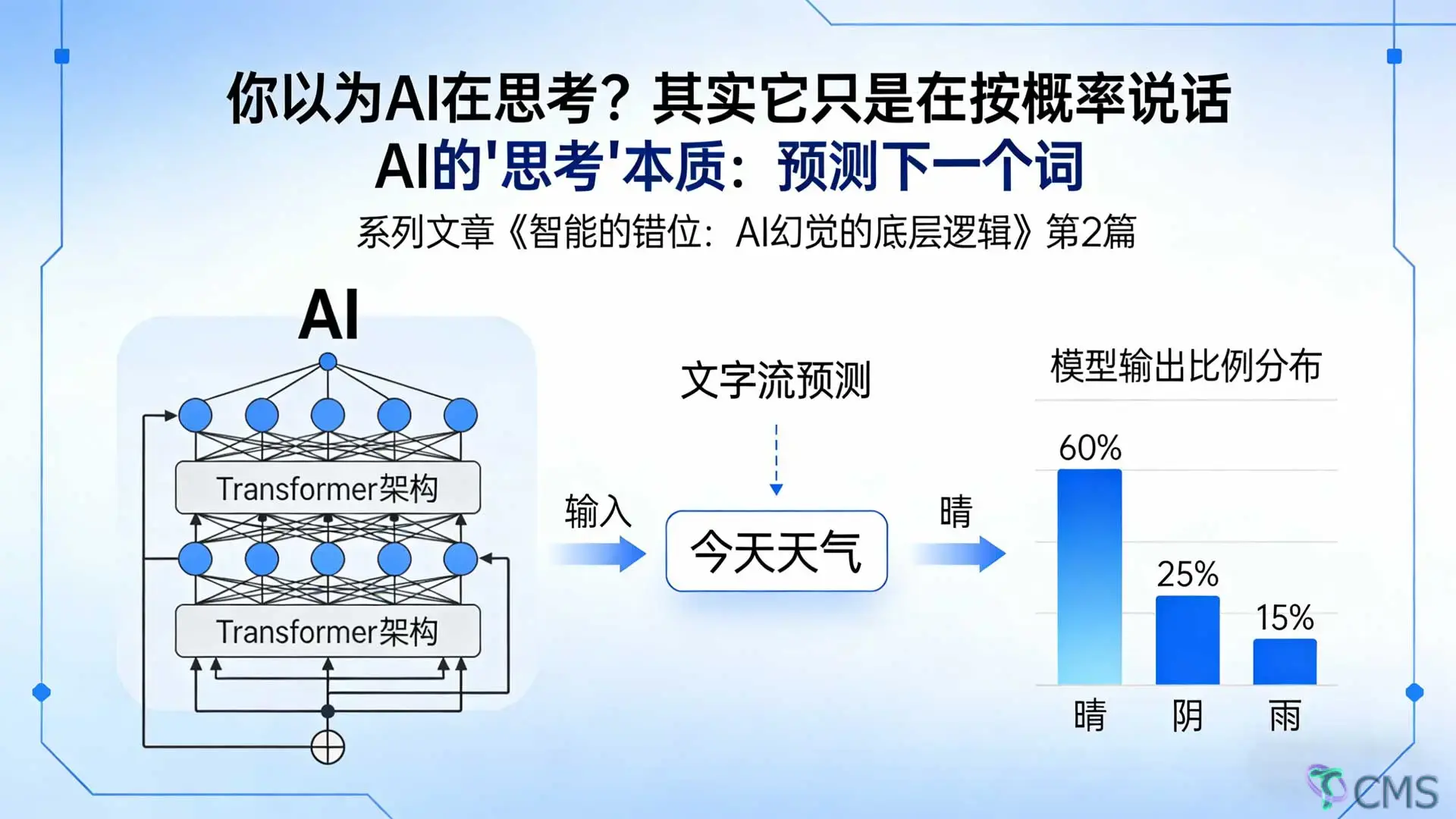
AI 不是在理解你的问题,而是在计算"下一句最像人话的是什么"。
它的回答不是思考的结果,而是概率的产物。
这句话能瞬间击中读者的认知盲区:
AI 的"聪明"并不是我们以为的那种聪明——它只是概率统计的集大成者。
你问它一个问题,它回答得头头是道;你让它写一篇文章,它写得像模像样;你让它解释一个概念,它逻辑清晰、语气坚定。
于是很多人以为:"AI 已经能思考了。"
但事实是:
AI 的回答不是思考的结果,而是概率的结果。
当你问 AI "法国的首都是哪里?",它不是在脑海中检索知识,而是在计算:在"法国的首都是"这串文字后面,接"巴黎"的概率是89%,接"伦敦"的概率是3%,接"香蕉"的概率是0.0001%。然后它选了概率最高的那个。
这不是思考,这是概率计算。
语言模型的底层逻辑只有一句话:
"根据前面的内容,预测最可能出现的下一个词。"
它不是在理解你的问题,不是在推理你的意图,更不是在判断真假。它只是在做一件事:计算概率。
你可以把它想象成一个超级复杂的"输入法联想功能"。当你在手机上打字,输入"今天天气",输入法会联想"很好"、"不错"、"真热"。它不是真的知道今天天气如何,它只是根据统计规律预测:大部分人说这句话时,后面接这些词的概率最高。
AI 做的是同样的事,只是规模大了几亿倍。它"见过"的文本越多,预测就越准,回答就越像人类——但它始终只是在预测概率,而不是在思考问题。
要真正理解 AI 的"思考"方式,我们需要稍微深入一点,看看它到底是怎么工作的。
AI 的生成过程可以拆成三个步骤:
第一步:把你的输入切成一个个 token(词片段)。
什么是 token?简单说,就是 AI 处理文字的最小单位。在英文中,一个 token 大约是 4 个字母或 0.75 个单词;在中文中,一个汉字通常对应 1-2 个 token。比如"你好,世界"可能被切成 ["你", "好", ",", "世", "界"] 共 5 个 token。
第二步:计算所有可能的"下一个 token"的概率。
模型会计算:在当前的上下文后面,接哪个 token 的概率最高?这个计算涉及数十亿个参数,但它本质上就是在做概率预测。
第三步:选出概率最高的那个。
然后继续预测下一个、再下一个……直到生成一段完整的回答。
这是一种"语言自动补全",只是比你手机输入法强一万倍。你手机输入法只见过你打过的字,而 AI "见过"互联网上几乎所有的公开文本。
AI 并不是理解了你的问题,而是它在训练数据里见过:类似的问法、类似的解释、类似的逻辑结构。
比如你问它"什么是量子纠缠?",它不是真的懂量子物理,而是它在数百万篇科普文章、论文、论坛讨论中见过无数次"量子纠缠"这个词的上下文。它知道这个词通常出现在什么样的句子里,后面通常会接什么样的解释,用什么语气、什么结构。
它会把这些模式拼接、重组、优化,生成一个"看起来像理解了"的回答。
这不是思考,是模式拟合——就像一个从没学过物理的人,背下了所有物理考试的"标准答案模板",他能在考试中拿高分,但他并不理解那些公式真正的含义。
AI 并不是懂论文结构,而是它学到:论文通常有摘要、引言、方法、实验、结论;代码通常有函数、变量、注释、逻辑块。
它不是理解了内容,而是掌握了"语言结构"。这就是为什么它能写出"像论文的论文",但有时会写出"看似正确但无法运行的代码"。
有研究数据显示,AI 现在生成了全球约 41% 的代码。但另一项研究发现,使用 AI 辅助编程后,代码的重构比例从 25% 下降到不足 10%——这意味着 AI 加速了开发,但可能牺牲了代码的可维护性和质量。
AI 写的代码能跑,不代表它"理解"了代码的逻辑;AI 写的论文像论文,不代表它"懂"论文的内容。它只是学会了"这个结构通常长什么样"。
这是理解 AI 幻觉的关键:概率高不代表事实对。
当 AI 不知道答案时,它不会说"我不知道"。它会继续预测:哪个词最可能出现?哪种句子最像人类会说的?哪种逻辑链最常见?
于是它会生成一个"看起来合理"的回答,但这个回答可能完全是假的。
举个例子(假设性示例):你问它"爱因斯坦是在哪一年发明电话的?"它可能会回答:"爱因斯坦在1876年发明了电话。"——听起来很像真的,有年份、有人名、有因果关系。但事实是:电话是贝尔在1876年发明的,跟爱因斯坦毫无关系。
AI 为什么会这样回答?因为"爱因斯坦"和"发明"经常一起出现,"1876"和"电话"经常一起出现,所以它把这些"高概率组合"拼在了一起。它不是在撒谎,它只是在做它最擅长的事:概率预测。
AI 学到的不是知识,而是:人类的语气、人类的表达方式、人类的逻辑节奏、人类的写作风格。
它从海量文本中学到:专业人士回答问题时通常用什么语气?学术论文通常用什么结构?科普文章通常用什么节奏?辩论时通常怎么组织论点?
它模仿得越像,你就越以为它"理解了"。但模仿理解和真正理解,是两回事。
这就像一个从没去过法国的人,看了一万篇关于法国的文章,学会了用"巴黎腔"描述法国。他能说得绘声绘色,但这不代表他真的理解法国。
这是 AI 幻觉最让人困惑的地方:你越追问,它越离谱。
原因在于:AI 的每一次回答,都是基于"前面所有的内容"来预测"下一个最可能的内容"。如果你在追问中引入了一个错误前提,这个错误就会成为后续预测的基础。
举个例子(假设性示例):
你问:"《认知科学导论》这本书第三章讲什么?"
AI 回答:"第三章讨论感知与注意力的认知机制。"(听起来很专业)
你追问:"那第七章提到的'逆向认知假说'是谁提出的?"
AI 回答:"这个假说是由德国认知科学家汉斯·穆勒在2018年提出的。"(完全是编的)
问题在于:当你说"第七章提到的'逆向认知假说'"时,你已经把"这个假说存在"当作了前提。AI 不会质疑你的前提,它会基于这个前提继续预测——于是越补越假,越补越离谱。
这不是它"故意胡说",而是它的"概率引擎"在正常运作:基于前面的内容,预测最可能的后续。 只是前面的内容错了,后续自然也跟着错。
现在我们可以更清楚地看到:人类和 AI 的"智能",本质上是两种完全不同的东西。
人类思考基于:
AI 生成基于:
当你把"意义智能"当成"概率智能",误会就产生了。你以为它在思考,它只是在预测;你以为它理解了,它只是在拟合模式;你以为它知道答案,它只是在生成"最像答案的东西"。
它能回答复杂问题,是因为它见过太多类似的模式;它能写出像样的文章,是因为它学会了语言的结构;它能一本正经地胡说,是因为概率高不等于事实对。
AI 不是人类智能的延伸,而是另一种智能——概率智能。
理解这一点,我们才能:
理解"概率智能",是理解 AI 时代的第一步。
这是系列《智能的错位:AI 幻觉的底层逻辑》第 2 篇。
下一篇:《AI 的自信不是因为它知道,而是因为它学会了"装懂"》
——为什么 AI 总是信心满满?因为它的自信来自语气,而不是知识。
理解底层逻辑,是理解智能时代的第一步。


3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026
3月 16, 2026

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。