喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
LZW算法通过动态构建字符串-编码映射字典,实现高效无损压缩,在图像格式、数据传输等领域应用广泛。其优势在于对重复模式数据的高压缩率,但需注意字典管理与数据特征匹配。
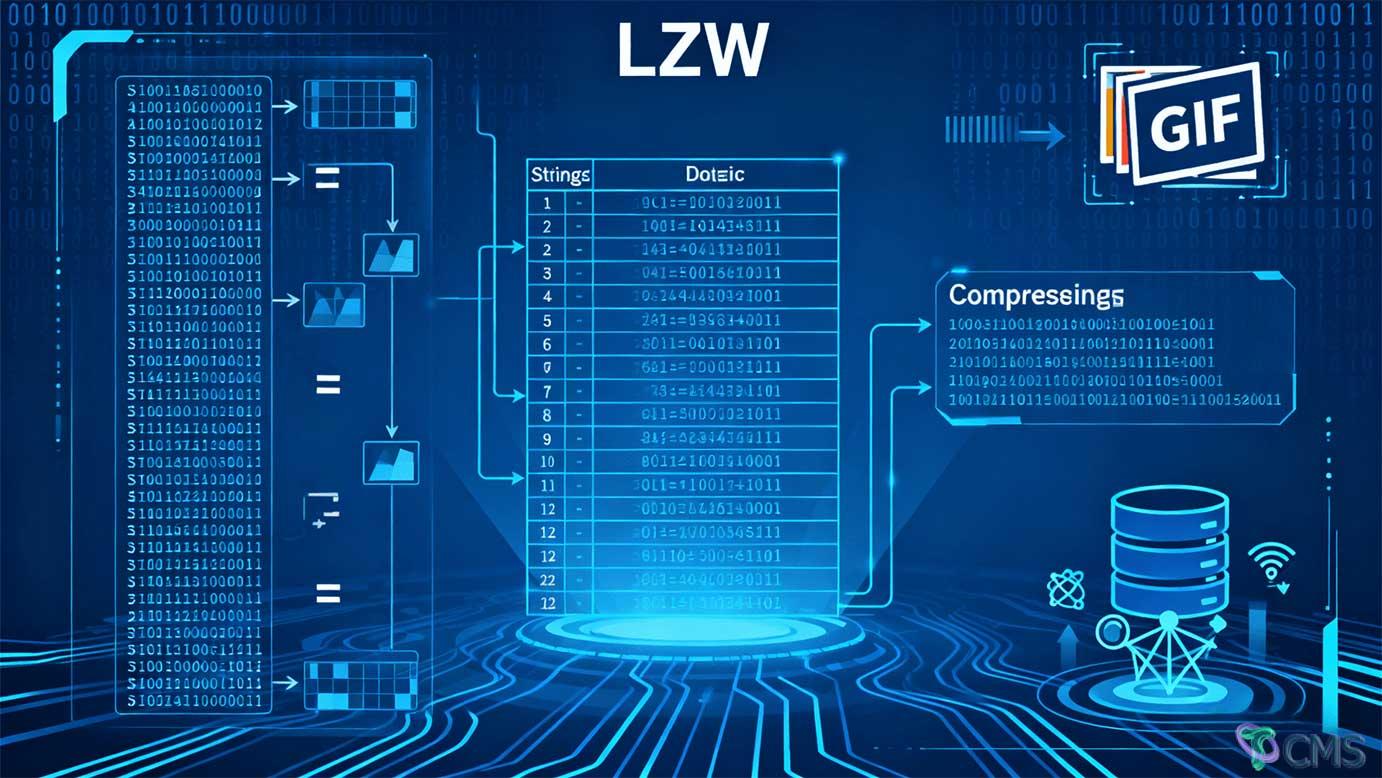
LZW算法通过动态构建字符串-编码映射字典,实现 ,在图像格式、数据传输等领域应用广泛。其优势在于对重复模式数据的高压缩率,但需注意字典管理与数据特征匹配。
LZW(Lempel-Ziv-Welch)算法是一种基于字典的无损数据压缩算法,核心思想是 用短代码替代重复出现的长字符串 ,通过动态构建字典实现高效压缩。
初始化字典 :编码开始时,字典包含所有可能的单字符(如ASCII码表中的0-255),每个字符映射到唯一的初始编码(如字符'A'对应65)。
编码过程 :从输入数据中不断读取字符,形成最长的、已在字典中的字符串 S ,输出其编码;然后将 S+下一个字符 作为新条目添加到字典,更新 S 为下一个字符,重复直至数据结束。
解码过程 :初始字典与编码时一致,读取编码值并输出对应字符串 S ;同时,将前一个输出字符串的首字符与当前字符串拼接,作为新条目添加到字典,逐步还原原始数据。
举例 :编码"TOBEORTOBEORTOBEOR"时,字典会动态记录"TO"“TOB”等组合,最终用短编码替代重复的长序列,实现压缩。
不同语言实现LZW算法的 核心逻辑一致:都遵循 LZW 算法的基本流程,包括初始化包含所有单字符的字典、动态添加新组合、处理压缩和解压的特殊情况。
package main
import (
"fmt"
)
// 压缩函数
func lzwCompress(data string) []int {
// 初始化字典
dictionary := make(map[string]int)
for i := 0; i < 256; i++ {
dictionary[string(rune(i))] = i
}
nextCode := 256
currentStr := ""
var compressed []int
for _, char := range data {
combined := currentStr + string(char)
if _, exists := dictionary[combined]; exists {
currentStr = combined
} else {
compressed = append(compressed, dictionary[currentStr])
dictionary[combined] = nextCode
nextCode++
currentStr = string(char)
}
}
// 处理剩余字符串
if currentStr != "" {
compressed = append(compressed, dictionary[currentStr])
}
return compressed
}
// 解压函数
func lzwDecompress(compressed []int) string {
if len(compressed) == 0 {
return ""
}
// 初始化字典
dictionary := make(map[int]string)
for i := 0; i < 256; i++ {
dictionary[i] = string(rune(i))
}
nextCode := 256
currentStr := dictionary[compressed[0]]
var decompressed string
decompressed += currentStr
for _, code := range compressed[1:] {
var entry string
if val, exists := dictionary[code]; exists {
entry = val
} else {
entry = currentStr + currentStr[:1]
}
decompressed += entry
dictionary[nextCode] = currentStr + entry[:1]
nextCode++
currentStr = entry
}
return decompressed
}
func main() {
original := "TOBEORTOBEORTOBEOR"
compressed := lzwCompress(original)
decompressed := lzwDecompress(compressed)
fmt.Printf("原始数据: %s\n", original)
fmt.Printf("压缩后: %v\n", compressed)
fmt.Printf("解压后: %s\n", decompressed)
fmt.Printf("压缩率: %.2f\n", float64(len(compressed)*2)/float64(len(original)*8))
}
def lzw_compress(data: str) -> list[int]:
# 初始化字典,包含所有单字符
dictionary = {chr(i): i for i in range(256)}
next_code = 256
current_str = ""
compressed = []
for char in data:
combined = current_str + char
if combined in dictionary:
current_str = combined
else:
# 输出当前字符串的编码
compressed.append(dictionary[current_str])
# 添加新组合到字典
dictionary[combined] = next_code
next_code += 1
current_str = char
# 处理最后一个字符串
if current_str:
compressed.append(dictionary[current_str])
return compressed
def lzw_decompress(compressed: list[int]) -> str:
if not compressed:
return ""
# 初始化字典
dictionary = {i: chr(i) for i in range(256)}
next_code = 256
current_str = chr(compressed[0])
decompressed = [current_str]
for code in compressed[1:]:
if code in dictionary:
entry = dictionary[code]
else:
# 处理特殊情况:新组合未在字典中
entry = current_str + current_str[0]
decompressed.append(entry)
# 添加新组合到字典
dictionary[next_code] = current_str + entry[0]
next_code += 1
current_str = entry
return ''.join(decompressed)
# 使用示例
if __name__ == "__main__":
original = "TOBEORTOBEORTOBEOR"
compressed = lzw_compress(original)
decompressed = lzw_decompress(compressed)
print(f"原始数据: {original}")
print(f"压缩后: {compressed}")
print(f"解压后: {decompressed}")
print(f"压缩率: {len(compressed)*2 / len(original)*8:.2f}") # 假设每个编码用2字节import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class LZW {
// 压缩方法
public static List<Integer> compress(String data) {
// 初始化字典
Map<String, Integer> dictionary = new HashMap<>();
for (int i = 0; i < 256; i++) {
dictionary.put(String.valueOf((char) i), i);
}
int nextCode = 256;
String currentStr = "";
List<Integer> compressed = new ArrayList<>();
for (char c : data.toCharArray()) {
String combined = currentStr + c;
if (dictionary.containsKey(combined)) {
currentStr = combined;
} else {
compressed.add(dictionary.get(currentStr));
dictionary.put(combined, nextCode);
nextCode++;
currentStr = String.valueOf(c);
}
}
// 处理剩余字符串
if (!currentStr.isEmpty()) {
compressed.add(dictionary.get(currentStr));
}
return compressed;
}
// 解压方法
public static String decompress(List<Integer> compressed) {
if (compressed.isEmpty()) {
return "";
}
// 初始化字典
Map<Integer, String> dictionary = new HashMap<>();
for (int i = 0; i < 256; i++) {
dictionary.put(i, String.valueOf((char) i));
}
int nextCode = 256;
String currentStr = dictionary.get(compressed.get(0));
StringBuilder decompressed = new StringBuilder(currentStr);
for (int i = 1; i < compressed.size(); i++) {
int code = compressed.get(i);
String entry;
if (dictionary.containsKey(code)) {
entry = dictionary.get(code);
} else {
entry = currentStr + currentStr.charAt(0);
}
decompressed.append(entry);
dictionary.put(nextCode, currentStr + entry.charAt(0));
nextCode++;
currentStr = entry;
}
return decompressed.toString();
}
public static void main(String[] args) {
String original = "TOBEORTOBEORTOBEOR";
List<Integer> compressed = compress(original);
String decompressed = decompress(compressed);
System.out.println("原始数据: " + original);
System.out.println("压缩后: " + compressed);
System.out.println("解压后: " + decompressed);
System.out.println("压缩率: " + (double) (compressed.size() * 2) / (original.length() * 8));
}
}<?php
function lzwCompress($data) {
// 初始化字典
$dictionary = array();
for ($i = 0; $i < 256; $i++) {
$dictionary[chr($i)] = $i;
}
$nextCode = 256;
$currentStr = "";
$compressed = array();
for ($i = 0; $i < strlen($data); $i++) {
$char = $data[$i];
$combined = $currentStr . $char;
if (isset($dictionary[$combined])) {
$currentStr = $combined;
} else {
$compressed[] = $dictionary[$currentStr];
$dictionary[$combined] = $nextCode;
$nextCode++;
$currentStr = $char;
}
}
// 处理剩余字符串
if ($currentStr !== "") {
$compressed[] = $dictionary[$currentStr];
}
return $compressed;
}
function lzwDecompress($compressed) {
if (empty($compressed)) {
return "";
}
// 初始化字典
$dictionary = array();
for ($i = 0; $i < 256; $i++) {
$dictionary[$i] = chr($i);
}
$nextCode = 256;
$currentStr = $dictionary[$compressed[0]];
$decompressed = $currentStr;
for ($i = 1; $i < count($compressed); $i++) {
$code = $compressed[$i];
if (isset($dictionary[$code])) {
$entry = $dictionary[$code];
} else {
$entry = $currentStr . $currentStr[0];
}
$decompressed .= $entry;
$dictionary[$nextCode] = $currentStr . $entry[0];
$nextCode++;
$currentStr = $entry;
}
return $decompressed;
}
// 使用示例
$original = "TOBEORTOBEORTOBEOR";
$compressed = lzwCompress($original);
$decompressed = lzwDecompress($compressed);
echo "原始数据: " . $original . "\n";
echo "压缩后: " . implode(", ", $compressed) . "\n";
echo "解压后: " . $decompressed . "\n";
echo "压缩率: " . (count($compressed)*2 / strlen($original)*8) . "\n";
?>
using namespace std;
// LZW压缩函数
vector<int> lzw_compress(const string& data) {
// 初始化字典,包含所有单字符
map<string, int> dictionary;
for (int i = 0; i < 256; ++i) {
dictionary[string(1, static_cast<char>(i))] = i;
}
int next_code = 256;
string current_str;
vector<int> compressed;
for (char c : data) {
string combined = current_str + c;
// 如果组合字符串在字典中存在,则继续扩展
if (dictionary.find(combined) != dictionary.end()) {
current_str = combined;
} else {
// 输出当前字符串的编码
compressed.push_back(dictionary[current_str]);
// 将新组合添加到字典
dictionary[combined] = next_code++;
current_str = string(1, c);
}
}
// 处理最后一个字符串
if (!current_str.empty()) {
compressed.push_back(dictionary[current_str]);
}
return compressed;
}
// LZW解压缩函数
string lzw_decompress(const vector<int>& compressed) {
if (compressed.empty()) {
return "";
}
// 初始化字典,包含所有单字符
map<int, string> dictionary;
for (int i = 0; i < 256; ++i) {
dictionary[i] = string(1, static_cast<char>(i));
}
int next_code = 256;
string current_str = dictionary[compressed[0]];
string decompressed = current_str;
for (size_t i = 1; i < compressed.size(); ++i) {
int code = compressed[i];
string entry;
// 查找当前编码对应的字符串
if (dictionary.find(code) != dictionary.end()) {
entry = dictionary[code];
} else {
// 处理特殊情况:编码尚未在字典中
entry = current_str + current_str[0];
}
decompressed += entry;
// 将新组合添加到字典
dictionary[next_code++] = current_str + entry[0];
current_str = entry;
}
return decompressed;
}
int main() {
// 测试数据
string original = "TOBEORTOBEORTOBEOR";
cout << "原始数据: " << original << endl;
// 压缩
vector<int> compressed = lzw_compress(original);
cout << "压缩后编码: ";
for (int code : compressed) {
cout << code << " ";
}
cout << endl;
// 解压缩
string decompressed = lzw_decompress(compressed);
cout << "解压后数据: " << decompressed << endl;
// 验证是否完全还原
if (original == decompressed) {
cout << "验证结果: 压缩解压成功,数据完全一致" << endl;
} else {
cout << "验证结果: 错误,数据不一致" << endl;
}
// 计算压缩率
double original_size = original.size() * 8; // 假设每个字符8位
double compressed_size = compressed.size() * 12; // 假设使用12位存储编码
double compression_ratio = compressed_size / original_size;
cout << "压缩率: " << compression_ratio << " (" << compressed_size << " bits / " << original_size << " bits)" << endl;
return 0;
}
字典大小控制 :若输入数据过大,字典可能无限增长,需设置最大条目数(如4096),满员后重置字典,平衡压缩率与内存占用。
预处理优化 :对重复率低的数据(如随机二进制),LZW压缩效果差,可先进行哈希或分组处理,提升重复模式识别率。
编码格式选择 :压缩后的编码值可用变长整数(如12位、16位)存储,减少冗余位,进一步降低体积。
压缩率波动 :对高重复数据(如HTML源码)压缩率可达50%以上,对低重复数据可能膨胀,需结合数据特征选择算法。
解码依赖字典同步 :编码与解码的字典构建过程必须完全一致,否则会导致解压错误,需确保双方初始字典和更新逻辑相同。
计算开销 :动态字典的查找和更新(尤其哈希表操作)可能影响性能,适合中小规模数据处理。
10月 30, 2025
10月 30, 2025
10月 30, 2025

10月 30, 2025

10月 22, 2025

5月 03, 2025
5月 03, 2025

5月 03, 2025

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。