喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
本文系统解析 AI 模型行业通用的命名规则与标签含义,助力模型选型和本地部署。文章先梳理出 “厂商 / 系列 - 版本号 - 参数量 - 模态 / 能力 - 微调类型 - 训练特性 - 量化 / 文件格式” 的通用命名结构,再按使用场景详解核心能力、训练压缩、量化格式、语言领域等全量通用标签及高频缩写。同时对比开源平台、量化模型、主流厂商的命名规范差异,并通过三个典型模型名实战拆解解读逻辑,让读者快速读懂各类 AI 模型名称的核心信息
在AI模型本地部署、开源项目协作的日常场景中,我们总能遇到各种让人眼花缭乱的模型名:google_gemma-3-270m-it-qat-Q4_K_M.gguf、Qwen3-VL-8B-Instruct、DeepSeek-R1-Distill-Llama-8B-UD-IQ1_M.gguf……
这些名称里的it、qat、Instruct、Q4_K_M等标签,并非随意堆砌,而是AI行业历经迭代形成的通用命名约定。无论是Hugging Face、ModelScope的开源模型,还是llama.cpp社区的量化模型,都遵循着核心命名逻辑。
本文将系统拆解AI模型命名的底层规则、全量通用标签含义,以及不同场景下的命名规范对比,帮你彻底读懂模型名,快速选型、高效部署。
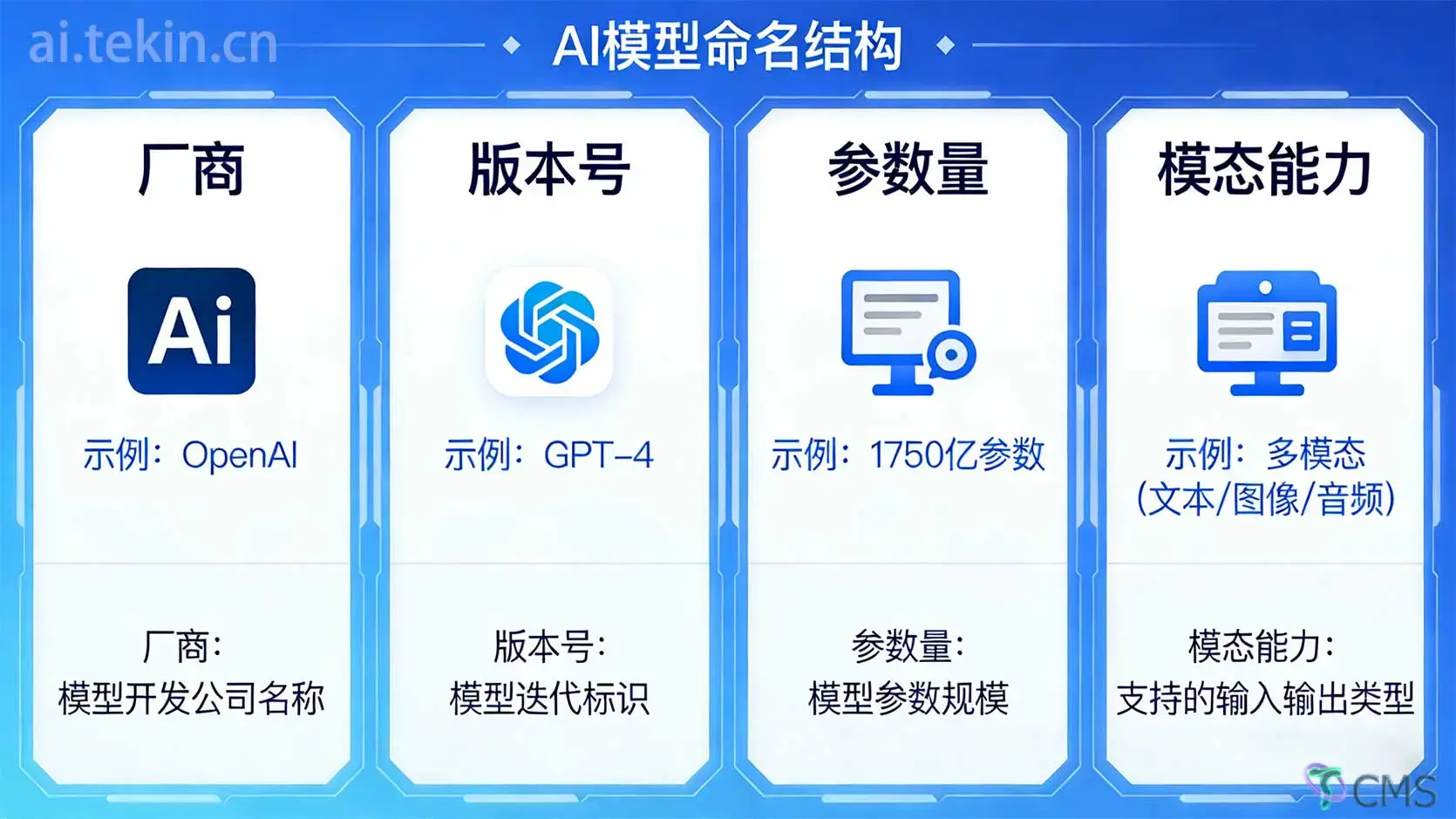
所有AI模型的命名,无论厂商、格式,都遵循“从核心到细节”的层级结构,越靠前的字段越关键,越靠后越偏向技术实现细节。
通用结构公式:
厂商/系列 - 版本号 - 参数量 - 模态/能力 - 微调类型 - 训练特性 - 量化/文件格式
| 位置 | 核心字段 | 含义 | 示例 |
|---|---|---|---|
| 1 | 厂商/系列 | 模型开发主体/产品系列 | Qwen(阿里通义)、Gemma(Google)、Llama(Meta) |
| 2 | 版本号 | 模型迭代版本 | 3、3.1、R1、Base |
| 3 | 参数量 | 模型核心参数规模 | 270m(2.7亿)、8B(80亿)、70B(700亿) |
| 4 | 模态/能力 | 模型核心功能/适用场景 | VL(多模态)、Chat(对话)、RAG(检索增强) |
| 5 | 微调类型 | 模型对齐方式/优化方向 | Instruct(指令调优)、Function(函数调用) |
| 6 | 训练特性 | 训练/压缩技术 | Distill(蒸馏)、MoE(混合专家)、QAT(量化感知训练) |
| 7 | 量化/格式 | 模型压缩方式/文件类型 | Q4_K_M(4bit量化)、GGUF(文件格式) |
关键规律:
K(千)、M(百万)、B(十亿),无歧义;Instruct/Chat/VL等必靠前,体现模型核心价值;以下标签覆盖主流开源模型、量化模型,按使用场景分类,附含义、适用场景及典型案例,新手可直接对照查阅。
这类标签决定模型“能做什么”,是选型的核心依据,跨厂商通用。
| 标签 | 全称 | 核心含义 | 适用场景 | 典型案例 |
|---|---|---|---|---|
| Base | Base Model | 基础预训练模型,未经过指令/对话对齐 | 二次微调、领域适配 | Qwen3-8B-Base、Llama-3-70B-Base |
| Instruct | Instruction Tuned | 指令微调模型,适配人类自然语言指令执行 | 通用问答、工具调用、轻量助手 | Qwen3-VL-8B-Instruct、Gemma-3-IT |
| IT | Instruct Tuned | Instruct的简写,语义完全一致 | Google/Gemma系列、开源社区量化模型 | gemma-3-270m-it、gemma-2-9b-it |
| Chat | Chat Model | 多轮对话优化,侧重对话流畅性与自然度 | 闲聊、客服、陪伴型助手 | Llama-3-8B-Chat、Qwen3-7B-Chat |
| Function | Function Calling | 工具/函数调用优化,支持API/代码执行 | 智能体、自动化工具、API对接 | Qwen-7B-Function、DeepSeek-Function |
| Tool | Tool Use | 与Function同义,侧重工具使用能力 | 插件生态、跨系统协作 | DeepSeek-Tool-LLM |
| RAG | Retrieval-Augmented Generation | 检索增强生成优化,适配知识库问答 | 企业知识库、文档问答、信息检索 | Phi-3-Context-Obedient-RAG |
| VL | Vision-Language | 多模态模型,支持图文理解/生成 | 看图问答、图像描述、视觉任务 | Qwen3-VL-8B-Instruct、BLIP-2-VL |
| Vision | Vision Model | 纯视觉模型,侧重图像/视频理解 | 图像分类、目标检测、视觉分析 | CLIP-Vision、ViT-B/32 |
| Code | Code Optimized | 代码生成/理解专用模型 | 编程辅助、代码调试、算法开发 | CodeLlama-7B-Code、DeepSeek-Coder |
| Math | Math Reasoning | 数学/逻辑推理优化模型 | 计算题、逻辑推导、学术计算 | DeepSeek-Math-7B、Qwen-Math-14B |
| Reasoning | Enhanced Reasoning | 强化推理能力,侧重逻辑链生成 | 复杂问题拆解、多步骤推理 | Llama-3-70B-Reasoning |
这类标签体现模型的训练方式、架构特性,影响模型性能、体积与推理效率。
| 标签 | 全称 | 核心含义 | 特点 | 典型案例 |
|---|---|---|---|---|
| SFT | Supervised Fine-Tuning | 监督微调,基础对齐方式 | 最常用,适配场景广 | Qwen-7B-SFT、Llama-3-8B-SFT |
| DPO | Direct Preference Optimization | 偏好对齐算法,优化生成质量 | 比SFT更自然,幻觉更少 | DeepSeek-DPO-7B、Qwen-DPO-14B |
| ORPO | Odds Ratio Preference Optimization | 轻量化偏好对齐,训练成本低 | 资源友好,效果接近DPO | Llama-3-8B-ORPO、Phi-3-ORPO |
| Distill | Distilled | 模型蒸馏,压缩大模型为小模型 | 体积更小、推理更快,精度略有损失 | DeepSeek-R1-Distill-Llama-8B |
| MoE | Mixture of Experts | 混合专家架构,高效大模型 | 参数量大但推理效率高,成本低 | Qwen-14B-MoE、DeepSeek-MoE-32B |
| Merge | Merged Model | 模型合并,社区/厂商多模型融合 | 融合多个模型优势,适配多场景 | Llama-3-Merge-8B、Qwen-Merge-14B |
| Context / 8k/32k/128k | Context Window | 上下文窗口长度,支持的最大文本长度 | 越长,能处理的文本越多 | Phi-3-Context-128k、Llama-3-70B-32k |
这类标签仅出现在量化模型文件(.gguf/.bin)中,是llama.cpp社区的通用约定,直接决定模型在本地的部署成本与性能。
| 标签 | 位宽 | 核心定位 | 精度表现 | 推荐场景 |
|---|---|---|---|---|
| FP32 | 32bit | 原始全精度模型 | 最高,无损失 | 科研、基准测试,本地部署不推荐 |
| FP16 | 16bit | 半精度模型 | 高,轻微损失 | 高性能设备推理,基准对比 |
| Q8_0 | 8bit | 高保真量化 | 极高,接近FP16 | 高性能本地部署(显存/内存充足) |
| Q6_K | 6bit | 高质量量化 | 高,速度优于Q8_0 | 中高端设备,追求平衡 |
| Q5_K_M | 5bit | 综合最佳量化 | 良,速度/精度平衡 | 本地部署主力选择(16G内存+) |
| Q4_K_M | 4bit | 高性价比量化 | 良,体积小、速度快 | 主流本地部署(8G/16G内存,首选) |
| Q3_K_M | 3bit | 轻量化量化 | 中,体积大幅压缩 | 低配置设备(4G/8G内存) |
| IQ2_XXS / IQ1_M | 1-2bit | 极限压缩量化 | 低,精度损失明显 | 极低配置设备(4G内存内),应急使用 |
| 标签 | 全称 | 核心含义 | 精度优势 | 典型案例 |
|---|---|---|---|---|
| QAT | Quantization-Aware Training | 量化感知训练,训练阶段适配量化 | 比普通量化精度高10%-30% | gemma-3-270m-it-qat、Qwen-8B-qat-Q4_K_M |
| PTQ | Post-Training Quantization | 后训练量化,训练完成后量化 | 常规精度,无额外训练成本 | 大部分开源量化模型 |
这类标签标注模型的语言适配性、领域适配方向,快速筛选场景化模型。
| 缩写 | 全称 | 含义 |
|---|---|---|
| IT | Instruct Tuned | 指令调优 |
| SFT | Supervised Fine-Tuning | 监督微调 |
| DPO | Direct Preference Optimization | 直接偏好优化 |
| ORPO | Odds Ratio Preference Optimization | 比值偏好优化 |
| QAT | Quantization-Aware Training | 量化感知训练 |
| PTQ | Post-Training Quantization | 后训练量化 |
| MoE | Mixture of Experts | 混合专家 |
| VL | Vision-Language | 视觉语言 |
| RAG | Retrieval-Augmented Generation | 检索增强生成 |
| UD | Universal Domain | 通用领域(DeepSeek专属) |
不同平台、不同模型类型的命名规范略有差异,但核心标签通用。以下是主流场景的规范对比,帮你在不同平台选型时不踩坑。
| 规范维度 | Hugging Face | ModelScope | 共性 |
|---|---|---|---|
| 核心结构 | 厂商/作者/项目 - 版本 - 参数量 - 能力 - 微调类型 | 厂商/系列 - 版本 - 参数量 - 能力 - 微调类型 | 遵循“核心→细节”结构,参数量、能力标签通用 |
| 命名分隔符 | 多用-,部分用_ | 多用_,兼容- | 分隔符无强制规范,不影响语义理解 |
| 量化标签 | 仅量化模型(.gguf)包含,后置 | 仅量化模型(.gguf)包含,后置 | 量化标签位置、含义完全一致 |
| 特殊标签 | 社区自定义标签多(如-chatml) | 阿里系标签统一(如-instruct) | 核心功能标签(Instruct/VL)通用 |
| 示例 | meta-llama/Llama-3-8B-Instruct | qwen/Qwen3-VL-8B-Instruct | 结构、核心标签完全一致 |
不同厂商有细微的命名习惯,但核心标签通用,选型时可快速适配。
| 厂商 | 核心系列 | 命名习惯 | 典型案例 |
|---|---|---|---|
| 阿里(通义) | Qwen | 多用Instruct/VL,参数量用B/M | Qwen3-VL-8B-Instruct、Qwen-7B-Function |
| Gemma | 多用IT替代Instruct,版本号简洁 | Gemma-3-270m-it、Gemma-2-9B-it-Q5_K_M | |
| Meta | Llama | 版本号明确(3/3.1),Chat/Instruct标签清晰 | Llama-3-8B-Chat、Llama-3-70B-Instruct |
| DeepSeek | DeepSeek | 多用Distill/UD/MoE,侧重推理优化 | DeepSeek-R1-Distill-Llama-8B、DeepSeek-MoE-32B |
| Microsoft | Phi | 多用Context/Obedient/RAG,轻量化 | Phi-3-Context-Obedient-RAG-Q4_K_M |
结合上述规范,拆解3个高频模型名,帮你快速掌握命名解读逻辑,做到“扫一眼就懂”。

3月 17, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

3月 16, 2026

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。